Chortle-crf was developed by Francis et al at University of
Toronto, and was presented at 28th Design Automation
Conference [4] in 1991. They are also the authors
of [1]. Chortle-crf consists of the following three
steps:
Bin-Packing Decomposition
This step utilizes unused pins of
LUT's to minimize their total number. Figure 0.1 shows
the operations in this step. In (a), a logic function is represented
by a AND-OR network. Without optimization, six LUT's are needed
(from u to z). The LUT u has two unused input pins, and w
does two. By putting a part of OR function into u and w, the
number of LUT's reduces from 6 to 4 (Figure 0.1 (b)).
Note that still has one unused pin and also y uses only two
input pins. These unused pins are used to implement the rest of OR
function
in z (Figure 0.1 (c)).
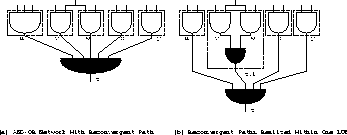
Reconvergent Paths Exploitation
Figure 0.2 shows
how exploitation of reconvergent paths can reduce the number of
LUT's. In Figure (a), LUT v and w share an input, and their
output converge at z. In Figure (b) v and w are merged, and
part of OR function of z is implemented in . The number of
LUT's reduces from 6 to 5.
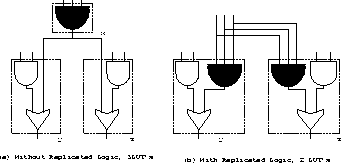
Fanout Nodes Replication
By replicating the function of a
fanout node, it may be embedded into the LUT's of of the following
stage. In Figure 0.3 (a), the shaded AND implements
a fanout node to y and z. It is replicated and embedded
into y and z. The total number of LUT's is reduced by one.
Figure: Reconvergent Paths Exploitation in Chortle-crf
In [1], performance comparison of mis-pga and
chortle-crf is found. When these two algorithms are applied
to map 27 MCNC networks into circuits of 5-input LUT's, mi-pga
requires 14% fewer LUT's than Chortle-crf, but 47 times slower.
Figure: Replication of Logic at a Fanout Node in Chortle-crf



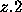 still has one unused pin and also y uses only two
input pins. These unused pins are used to implement the rest of OR
function
in z (Figure 0.1 (c)).
still has one unused pin and also y uses only two
input pins. These unused pins are used to implement the rest of OR
function
in z (Figure 0.1 (c)).
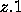 . The number of
LUT's reduces from 6 to 5.
. The number of
LUT's reduces from 6 to 5.